Bagi Jae Lee, seorang ilmuwan data dengan pelatihan, tidak pernah masuk akal bahwa video — yang telah menjadi bagian besar dari hidup kita, apalagi dengan munculnya platform seperti TikTok, Vimeo, dan YouTube — sulit untuk ditelusuri karena kendala teknis. ditimbulkan oleh pemahaman konteks. Mencari judul, deskripsi, dan tag video selalu cukup mudah, tidak memerlukan lebih dari algoritme dasar. Tapi mencari di dalam video untuk momen dan adegan tertentu jauh di luar kemampuan teknologi, terutama jika momen dan adegan itu tidak diberi label dengan cara yang jelas.
Untuk mengatasi masalah ini, Lee, bersama teman-teman dari industri teknologi, membangun layanan cloud untuk pencarian dan pemahaman video. Itu menjadi Twelve Labs, yang kemudian mengumpulkan $17 juta modal ventura — $12 juta di antaranya berasal dari putaran perpanjangan benih yang ditutup hari ini. Radical Ventures memimpin perpanjangan dengan partisipasi dari Index Ventures, WndrCo, Spring Ventures, CEO Weights & Biases Lukas Biewald dan lainnya, kata Lee kepada gerakanpintar.com melalui email.
“Visi Twelve Labs adalah untuk membantu pengembang membuat program yang dapat melihat, mendengarkan, dan memahami dunia seperti yang kami lakukan dengan memberi mereka infrastruktur pemahaman video yang paling kuat,” kata Lee.
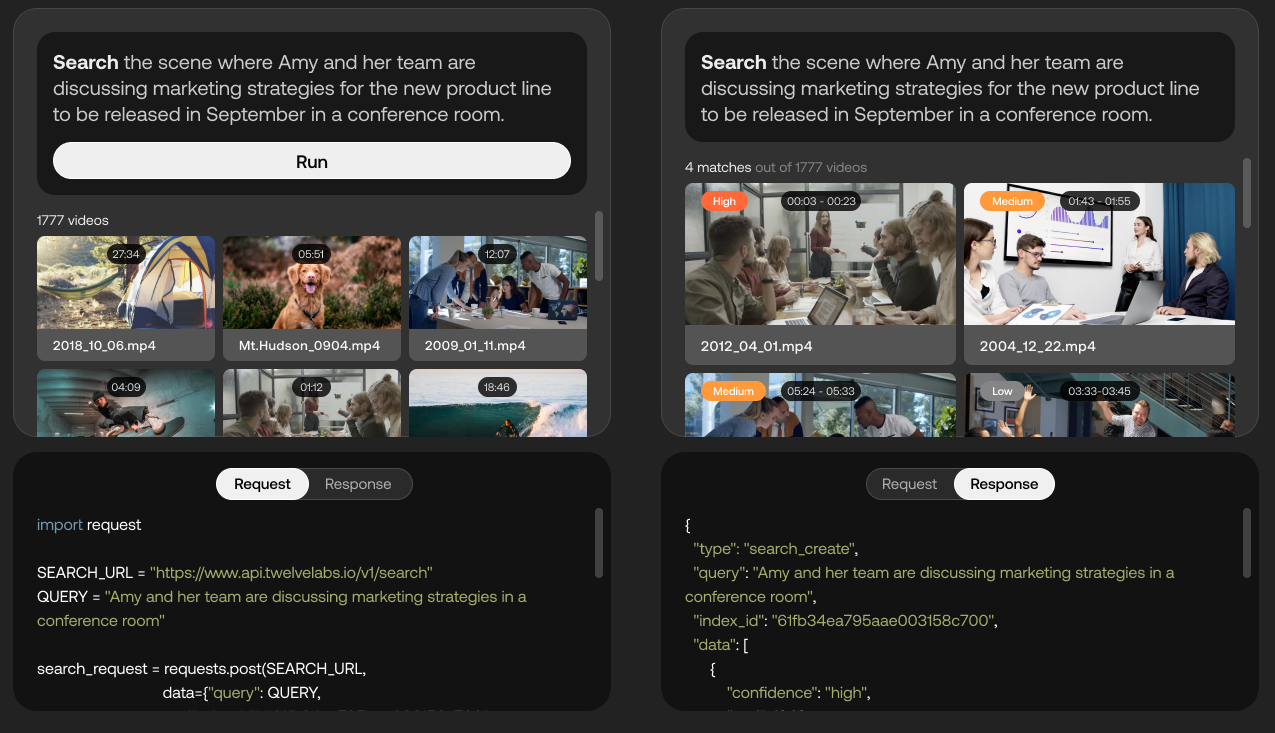
Demo kemampuan platform Twelve Labs. Kredit Gambar: Dua Belas Lab
Twelve Labs, yang saat ini dalam versi beta tertutup, menggunakan AI untuk mencoba mengekstrak “informasi kaya” dari video seperti gerakan dan tindakan, objek dan orang, suara, teks di layar, dan ucapan untuk mengidentifikasi hubungan di antara mereka. Platform mengubah berbagai elemen ini menjadi representasi matematis yang disebut “vektor” dan membentuk “koneksi sementara” antar bingkai, memungkinkan aplikasi seperti pencarian adegan video.
“Sebagai bagian dari pencapaian visi perusahaan untuk membantu pengembang membuat aplikasi video cerdas, tim Twelve Labs sedang membangun ‘model dasar’ untuk pemahaman video multimoda,” kata Lee. “Para pengembang akan dapat mengakses model-model ini melalui rangkaian API, tidak hanya melakukan pencarian semantik tetapi juga tugas-tugas lain seperti ‘baberisasi’ video bentuk panjang, pembuatan ringkasan, serta pertanyaan dan jawaban video.”
Google mengambil pendekatan serupa untuk memahami video dengan sistem AI MUM-nya, yang digunakan perusahaan untuk mendukung rekomendasi video di Google Penelusuran dan YouTube dengan memilih subjek dalam video (misalnya, “bahan lukisan akrilik”) berdasarkan audio, teks, dan visual. isi. Namun meskipun teknologinya mungkin sebanding, Twelve Labs adalah salah satu vendor pertama yang memasarkannya; Google telah memilih untuk menjaga MUM internal, menolak untuk menyediakannya melalui API publik.
Meskipun demikian, Google, serta Microsoft dan Amazon, menawarkan layanan (yaitu, Google Cloud Video AI, Azure Video Indexer, dan AWS Rekognition) yang mengenali objek, tempat, dan tindakan dalam video dan mengekstrak metadata yang kaya pada tingkat bingkai. Ada juga Reminiz, startup visi komputer Prancis yang mengklaim dapat mengindeks semua jenis video dan menambahkan tag ke konten rekaman dan streaming langsung. Tetapi Lee menegaskan bahwa Twelve Labs cukup terdiferensiasi — sebagian karena platformnya memungkinkan pelanggan menyempurnakan AI untuk kategori konten video tertentu.

Maket API untuk menyempurnakan model agar berfungsi lebih baik dengan konten terkait salad. Kredit Gambar: Dua Belas Lab
“Apa yang kami temukan adalah bahwa produk AI sempit yang dibuat untuk mendeteksi masalah tertentu menunjukkan akurasi tinggi dalam skenario ideal mereka dalam pengaturan yang terkontrol, tetapi tidak dapat diskalakan dengan baik ke data dunia nyata yang berantakan,” kata Lee. “Mereka bertindak lebih sebagai sistem berbasis aturan, dan karena itu kurang memiliki kemampuan untuk menggeneralisasi ketika terjadi perbedaan. Kami juga melihat ini sebagai batasan yang berakar pada kurangnya pemahaman konteks. Pemahaman konteks adalah apa yang memberi manusia kemampuan unik untuk membuat generalisasi di berbagai situasi yang tampaknya berbeda di dunia nyata, dan di sinilah Twelve Labs berdiri sendiri.”
Di luar pencarian, Lee mengatakan teknologi Twelve Labs dapat mendorong hal-hal seperti penyisipan iklan dan moderasi konten, dengan cerdas mencari tahu, misalnya, video yang menampilkan pisau yang mengandung kekerasan versus instruksional. Itu juga dapat digunakan untuk analitik media dan umpan balik waktu nyata, katanya, dan untuk secara otomatis menghasilkan gulungan sorotan dari video.
Sedikit lebih dari setahun setelah didirikan (Maret 2021), Twelve Labs memiliki pelanggan yang membayar – Lee tidak akan mengungkapkan berapa tepatnya – dan kontrak multi-tahun dengan Oracle untuk melatih model AI menggunakan infrastruktur cloud Oracle. Ke depan, startup berencana untuk berinvestasi dalam membangun teknologinya dan memperluas timnya. (Lee menolak untuk mengungkapkan jumlah tenaga kerja Twelve Labs saat ini, tetapi data LinkedIn menunjukkan sekitar 18 orang.)
“Bagi sebagian besar perusahaan, meskipun nilai besar yang dapat dicapai melalui model besar, sangat tidak masuk akal bagi mereka untuk melatih, mengoperasikan, dan memelihara model ini sendiri. Dengan memanfaatkan platform Twelve Labs, organisasi mana pun dapat memanfaatkan kemampuan pemahaman video yang kuat hanya dengan beberapa panggilan API intuitif,” kata Lee. “Arah masa depan inovasi AI mengarah langsung ke pemahaman video multimoda, dan Twelve Labs berada di posisi yang tepat untuk mendorong batasan lebih jauh lagi di tahun 2023.”