Musik yang dihasilkan AI sudah merupakan konsep yang cukup inovatif, tetapi Riffusion membawanya ke level lain dengan pendekatan yang cerdas dan aneh yang menghasilkan musik yang aneh dan menarik tidak menggunakan audio tetapi gambar-gambar audio.
Kedengarannya aneh, aneh. Tetapi jika berhasil, itu berhasil. Dan itu berhasil! Agak.
Difusi adalah teknik pembelajaran mesin untuk menghasilkan gambar yang memperkuat dunia AI selama setahun terakhir. DALL-E 2 dan Stable Diffusion adalah dua model profil paling tinggi yang bekerja dengan secara bertahap mengganti kebisingan visual dengan apa yang menurut AI harus terlihat seperti prompt.
Metode ini telah terbukti kuat dalam banyak konteks dan sangat rentan terhadap penyempurnaan, di mana Anda memberikan banyak jenis konten tertentu kepada model yang paling terlatih untuk membuatnya berspesialisasi dalam menghasilkan lebih banyak contoh konten tersebut. Misalnya, Anda dapat menyempurnakannya pada cat air atau pada foto mobil, dan itu terbukti lebih mampu mereproduksi salah satu dari hal-hal itu.
Apa yang dilakukan Seth Forsgren dan Hayk Martiros untuk proyek hobi mereka, Riffusion, adalah menyempurnakan Difusi Stabil pada spektogram.
“Hayk dan saya bermain di sebuah band kecil bersama, dan kami memulai proyek ini hanya karena kami menyukai musik dan tidak tahu apakah Stable Diffusion bahkan dapat membuat gambar spektogram dengan ketepatan yang cukup untuk diubah menjadi audio,” Forsgren memberi tahu gerakanpintar.com. “Di setiap langkah kami semakin terkesan dengan apa yang mungkin, dan satu ide mengarah ke ide berikutnya.”
Apa itu spektogram, Anda bertanya? Itu adalah representasi visual dari audio yang menunjukkan amplitudo frekuensi yang berbeda dari waktu ke waktu. Anda mungkin pernah melihat bentuk gelombang, yang menunjukkan volume dari waktu ke waktu dan membuat audio terlihat seperti serangkaian bukit dan lembah; bayangkan jika alih-alih hanya volume total, itu menunjukkan volume setiap frekuensi, dari ujung bawah ke ujung atas.
Inilah bagian yang saya buat dari sebuah lagu (“Marconi’s Radio” oleh Secret Machines, jika Anda bertanya-tanya):
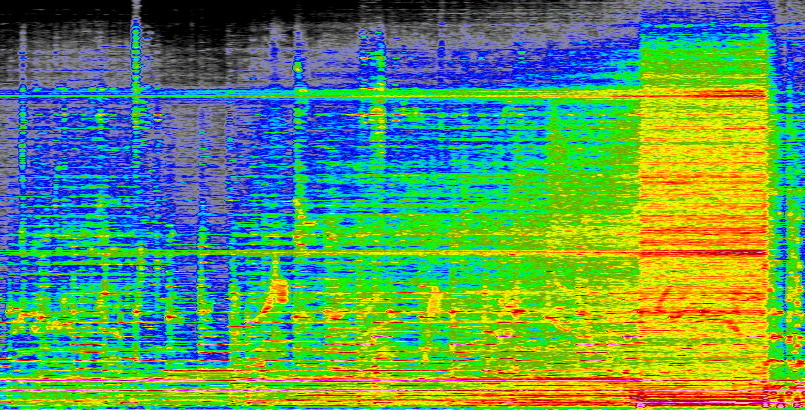
Kredit Gambar: Devin Coldewey
Anda dapat melihat bagaimana itu menjadi lebih keras di semua frekuensi saat lagu dibuat, dan Anda bahkan dapat melihat nada dan instrumen individual jika Anda tahu apa yang harus dicari. Prosesnya pada dasarnya tidak sempurna atau tanpa kerugian dengan cara apa pun, tetapi ini merupakan representasi suara yang akurat dan sistematis. Dan Anda dapat mengubahnya kembali menjadi suara dengan melakukan proses yang sama secara terbalik.
Forsgren dan Martiros membuat spektrogram sekumpulan musik dan menandai gambar yang dihasilkan dengan istilah yang relevan, seperti “gitar blues”, “piano jazz”, “afrobeat”, hal-hal seperti itu. Memberi makan model koleksi ini memberinya ide bagus tentang seperti apa suara tertentu “terlihat” dan bagaimana ia dapat membuat ulang atau menggabungkannya.
Beginilah proses difusi terlihat jika Anda mengambil sampelnya saat menyempurnakan gambar:

Kredit Gambar: Seth Forsgren / Hayk Martiros
Dan memang model tersebut terbukti mampu menghasilkan spektogram yang, ketika diubah menjadi suara, sangat cocok untuk perintah seperti “piano funky”, “saksofon jazzy”, dan seterusnya. Berikut contohnya:

Kredit Gambar: Seth Forsgren / Hayk Martiros
Tapi tentu saja spektogram persegi (512 x 512 piksel, resolusi Difusi Stabil standar) hanya mewakili klip pendek; lagu tiga menit akan menjadi persegi panjang yang jauh lebih luas. Tidak ada yang mau mendengarkan musik lima detik sekaligus, tetapi keterbatasan sistem yang mereka buat membuat mereka tidak bisa membuat spektrogram dengan tinggi 512 piksel dan lebar 10.000 piksel.
Setelah mencoba beberapa hal, mereka memanfaatkan struktur dasar model besar seperti Stable Diffusion, yang memiliki banyak “ruang laten”. Ini seperti tanah tak bertuan di antara node yang lebih terdefinisi dengan baik. Seperti jika Anda memiliki area model yang mewakili kucing, dan area lain yang mewakili anjing, yang ada “di antara” mereka adalah ruang laten yang, jika Anda hanya menyuruh AI untuk menggambar, akan menjadi semacam dogcat, atau catdog, meskipun tidak ada seperti itu.
Kebetulan, hal-hal ruang laten menjadi jauh lebih aneh dari itu:
Namun, tidak ada dunia mimpi buruk yang menyeramkan untuk proyek Riffusion. Sebaliknya, mereka menemukan bahwa jika Anda memiliki dua petunjuk, seperti “lonceng gereja” dan “ketukan elektronik”, Anda dapat berpindah dari satu ke yang lain sedikit demi sedikit dan secara bertahap dan mengejutkan secara alami memudar dari satu ke yang lain, pada ketukan genap:
Ini adalah suara yang aneh dan menarik, meskipun jelas tidak terlalu rumit atau dengan ketelitian tinggi; ingat, mereka bahkan tidak yakin bahwa model difusi dapat melakukan ini sama sekali, jadi fasilitas yang mengubah bel menjadi ketukan atau ketukan mesin tik menjadi piano dan bass cukup luar biasa.
Memproduksi klip dengan bentuk yang lebih panjang dimungkinkan tetapi masih teoretis:
“Kami belum benar-benar mencoba membuat lagu klasik berdurasi 3 menit dengan pengulangan chorus dan bait,” kata Forsgren. “Saya pikir itu bisa dilakukan dengan beberapa trik pintar seperti membuat model level yang lebih tinggi untuk struktur lagu, dan kemudian menggunakan model level yang lebih rendah untuk klip individual. Alternatifnya, Anda dapat melatih model kami secara mendalam dengan gambar beresolusi lebih besar dari lagu lengkap.”
Kemana perginya dari sini? Grup lain mencoba membuat musik yang dihasilkan AI dengan berbagai cara, mulai dari menggunakan model sintesis ucapan hingga audio yang dilatih khusus seperti Dance Diffusion.
Riffusion lebih merupakan demo “wow, lihat ini” daripada rencana besar apa pun untuk menemukan kembali musik, dan Forsgren mengatakan dia dan Martiros senang melihat orang-orang terlibat dengan pekerjaan mereka, bersenang-senang, dan mengulanginya:
“Ada banyak arah yang bisa kami tuju dari sini, dan kami bersemangat untuk terus belajar sepanjang jalan. Sangat menyenangkan melihat orang lain membangun ide mereka sendiri di atas kode kita pagi ini juga. Salah satu hal menakjubkan tentang komunitas Stable Diffusion adalah seberapa cepat orang membangun di atas segala sesuatu ke arah yang tidak dapat diprediksi oleh penulis aslinya.”
Anda dapat mengujinya dalam demo langsung di Riffusion.com, tetapi Anda mungkin harus menunggu sebentar untuk merender klip Anda — ini mendapat sedikit lebih banyak perhatian daripada yang diharapkan pembuatnya. Semua kode tersedia melalui halaman tentang, jadi jangan ragu untuk menjalankannya sendiri juga, jika Anda memiliki chip untuk itu.